hicancan的科研周报10.25
10.18-10.25科研学习
1. 学习使用mmWave studio采集毫米波雷达数据:
- 安装所需软件:mmWave studio、MATLAB等。
- 了解其基本功能和使用方法。
- 学习雷达信号参数设置。
- 学习使用mmWave studio进行雷达信号可视化和分析。
2 阅读文献《基于车载毫米波雷达动态手势识别网络》
2.1 学习该研究方向的背景和意义
- 相比于传统的图像手势识别:毫米波雷达可以通过发射电磁波并接收手势运动的回波来进行识别,因此可以不受光照影响,这是与图像手势识别相比的巨大优势。 同时毫米波雷达不需要采集车内图像信息,可以保护车内人员的隐私。
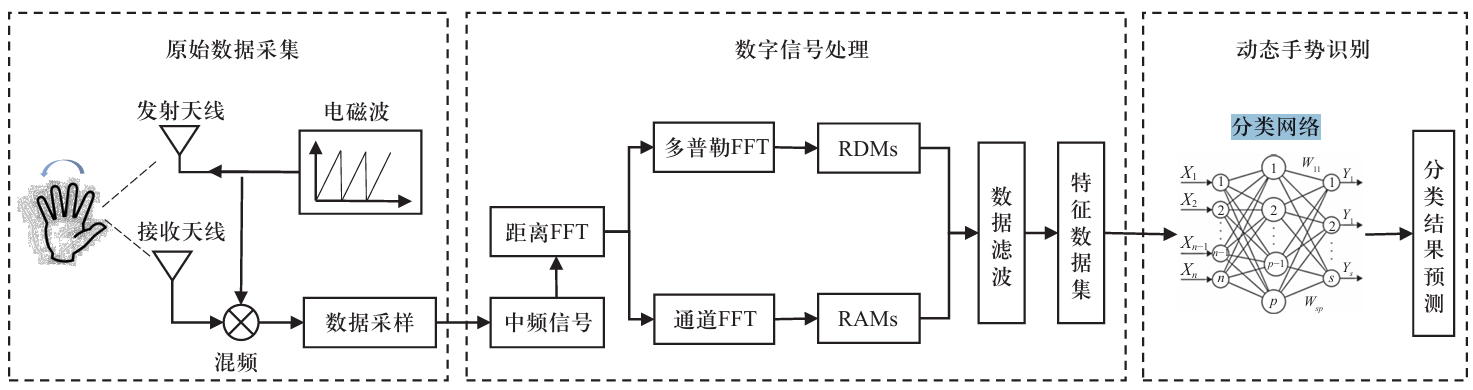
2.2 基于论文学习了动态手势识别算法数据处理
- 整个算法数据处理分为三个部分:
- 原始数据采集:使用毫米波雷达采集动态手势数据。
- 数字信号处理:对采集到的数据进行滤波、去噪等处理。
- 动态手势分类网络识别:从预处理后的数据中提取有用的特征,并使用深度学习算法进行手势分类。
2.3 学习了文中提出的动态手势识别网络模型
- 动态手势识别网络分为四个部分:
- 网络输入:距离-角度图RAM+距离-多普勒图RDM。
- 特征提取:经过两个3DCNN主干网络进行空间特征提取。
- 时间序列分析:利用Transformer编码器用来进行时序特征提取。
- 手势分类结果概率预测:经过一个全链接层进行分类。
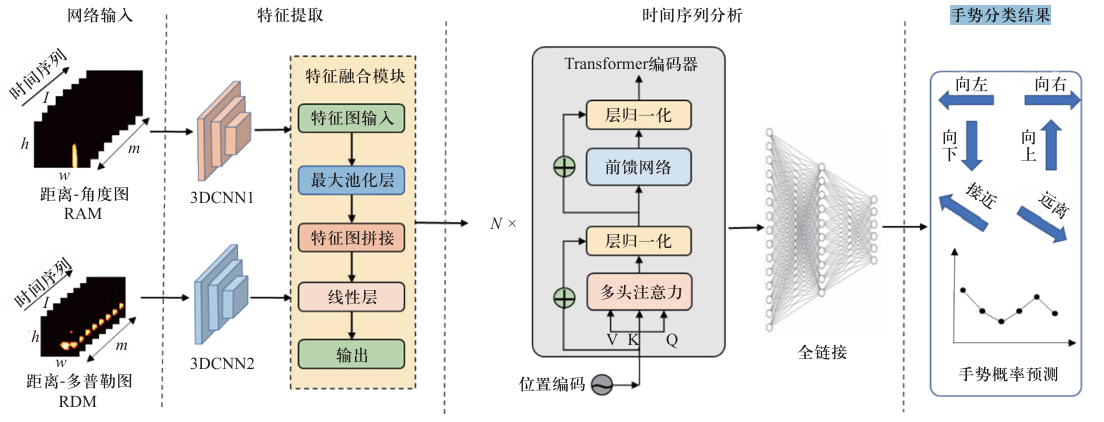
该网络模型的亮点:三维卷积网络(3DCNN)与Transformer的融合:通过将三维卷积网络用于空间特征提取,再结合Transformer模块进行时序特征编码,该模型能够同时捕捉手势的空间和时间特征,提高了识别的准确性。
2.4 学习如何提高数据集的多场景性以提高模型的泛化能力
- 考虑汽车:在加速、减速、怠速、匀速与转弯等各种场景产生的震动而带来的惯性干扰。
- 考虑人:避免车内人员换挡、转身等非指令动态被误识别。
- 考虑环境:避免车内外的其他环境噪声的动态变化也会对数据采集造成干扰
2.5 思考意义:RDM与RAM特征图处理前后以及对比实验结果
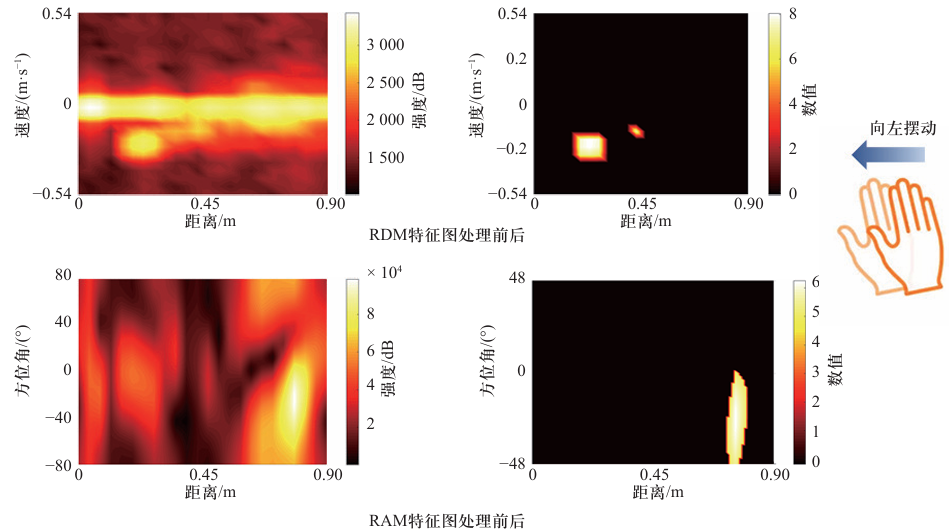
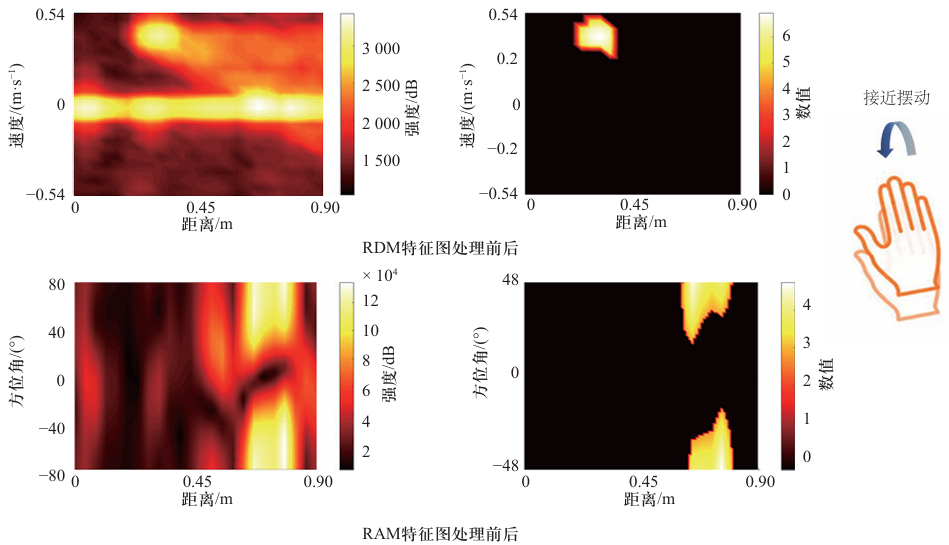

因此:
- 该文提出的算法达到了最高的平均分类精度97.14%,远好于传统的HMM算法. 仅采用3DCNN网络的分类准确率只有93.34%,
- 当加入LSTM和Transformer模块手势分类精度明显提高. 在3DCNN中添加Transformer模块要比LSTM模块分类准确率也增加1.1%
- 证明了Transformer模块的时序和空间编码方式在该分类任务中要优于LSTM网络
2.6 阅读小结
- 该文提出的基于毫米波雷达的动态手势识别算法,通过将3DCNN与Transformer模块相结合,实现了对动态手势的高精度识别。同时,该算法在处理数据时考虑了车内环境、人、汽车等影响因素,提高了数据集的多场景性,从而提高了模型的泛化能力。
- 该文提出的算法在动态手势识别任务中取得了较好的效果,为未来基于毫米波雷达的动态手势识别研究提供了新的思路和方法。
2.7 与WiFi结合的可能性以及论文迁移创想应用
- 该文提出的基于毫米波雷达的动态手势识别算法,可以迁移到基于WiFi的动态手势识别算法中,通过将WiFi信号处理后的特征图作为输入,利用3DCNN与Transformer模块进行手势识别,从而实现基于WiFi的动态手势识别。
- 可以尝试多模态融合,将毫米波雷达和WiFi信号处理后的特征图进行融合,利用3DCNN与Transformer模块进行手势识别,从而实现多模态的动态手势识别。
- 还可以应用于智能家居、智能驾驶等领域,为用户提供更加便捷、智能的服务。例如,在智能家居中,可以通过动态手势识别技术实现遥控家电、调节灯光等功能,从而更好的保护用户隐私,并避免光照影响。
2.8 查找代码进行学习
- 由于该文是发表在期刊上的,因此没有提供代码,需要自己查找。
- 复现过程中需要了解3DCNN、Transformer等深度学习模型的基本原理和实现方法,同时需要了解毫米波雷达信号处理的基本方法。
- 复现过程中需要使用Python编程语言,并使用PyTorch等深度学习框架进行模型的实现和训练。
- 复现过程中需要使用MATLAB等软件进行毫米波雷达信号的处理和分析。
- 复现过程中需要使用mmWave studio等软件进行毫米波雷达信号的采集和可视化。
查找学习3DCNN代码如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv3d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm3d(planes)
self.conv2 = nn.Conv3d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm3d(planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv3d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm3d(self.expansion*planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(ResNet, self).__init__()
self.in_planes = 64
self.conv1 = nn.Conv3d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm3d(64)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.linear = nn.Linear(512*block.expansion, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool3d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
def ResNet18():
return ResNet(BasicBlock, [2,2,2,2])解释代码:
- 该代码实现了一个基于3DCNN的动态手势识别算法,使用了ResNet18网络结构。
- BasicBlock是ResNet的基本模块,包含两个卷积层和一个shortcut连接。
- ResNet是整个网络结构,包含一个卷积层、四个BasicBlock层和一个全连接层。
- ResNet18是ResNet的一个变种,使用四个BasicBlock层。
- forward函数是网络的前向传播过程,输入为三维张量,输出为手势类别。
- 可以根据需要修改网络结构,例如增加或减少卷积层、全连接层等。
- 可以尝试使用其他3DCNN模型,例如VGG、Inception等。
查找学习Transformer代码如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
class Transformer(nn.Module):
def __init__(self, d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward, dropout=0.1):
super(Transformer, self).__init__()
self.transformer = nn.Transformer(d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward, dropout)
self.encoder = nn.Linear(d_model, d_model)
self.decoder = nn.Linear(d_model, d_model)
def forward(self, src, tgt):
src = self.encoder(src)
tgt = self.decoder(tgt)
output = self.transformer(src, tgt)
return output解释代码:
- 该代码实现了一个基于Transformer的动态手势识别算法。
- Transformer是整个网络结构,包含一个编码器、一个解码器和一个Transformer模块。编码器和解码器都是线性层。
- forward函数是网络的前向传播过程,输入为源序列和目标序列,输出为解码后的序列。
- 可以根据需要修改网络结构,例如增加或减少Transformer层、编码器和解码器等。
- 可以尝试使用其他序列到序列模型,例如LSTM、GRU等。
- 可以尝试使用其他注意力机制,例如自注意力、交叉注意力等。
总结
- 3DCNN模型可以用于动态手势识别,具有较好的实时性和准确性。
- Transformer模型可以用于动态手势识别,具有较好的并行性和长距离依赖性。
- 可以根据具体任务和数据集,选择合适的模型和参数进行训练和优化。
hicancan的科研周报10.25
https://hicancan.cn/2024/11/07/science10_25/